

Contents
|
|
So, what really is hashing?
TLDR:
- Hashing is generating a value or values from a string of text using a mathematical function.
- Hashing is one way to enable security during the process of message transmission when the message is intended for a particular recipient only. A formula generates the hash, which helps to protect the security of the transmission against tampering.
It is important to know how blockchain Hashing works. In order to do that, however, we need to first understand one of the core principles that go into blockchain creation. Blockchain technology is one of the most innovative and era-defining discoveries of the past century. Seeing the influence it has had over the last few years and the impact that it will have in the future, it surely isn’t an exaggeration to say that. In order to understand how various cryptocurrencies like Ethereum and Bitcoin function.
So what is hashing?
In simple terms, hashing means taking an input string of any length and giving out an output of a fixed length. In the context of cryptocurrencies like bitcoin, the transactions are taken as input and run through a hashing algorithm (bitcoin uses SHA-256) which gives an output of a fixed length.
Let’s see how the hashing process works. We are going put in certain inputs. For this exercise, we are going to use the SHA-256 (Secure Hashing Algorithm 256).

As you can see, in the case of SHA-256, no matter how big or small your input is, the output will always have a fixed 256-bits length. This becomes critical when you are dealing with a huge amount of data and transactions. So basically, instead of remembering the input data which could be huge, you can just remember the hash and keep track. Before we go any further we need to first see the various properties of hashing functions and how they get implemented in the blockchain.
Contents
Cryptographic hash functions
A cryptographic hash function is a special class of hash functions that has various properties making it ideal for cryptography. There are certain properties that a cryptographic hash function needs to have in order to be considered secure. Let’s run through them one by one.
Property 1: Deterministic
This means that no matter how many times you parse through a particular input through a hash function you will always get the same result. This is critical because if you get different hashes every single time it will be impossible to keep track of the input.
Property 2: Quick Computation
The hash function should be capable of returning the hash of input quickly. If the process isn’t fast enough then the system simply won’t be efficient.
Property 3: Pre-Image Resistance
What pre-image resistance states are that given H(A) it is infeasible to determine A, where A is the input and H(A) is the output hash. Notice the use of the word “infeasible” instead of “impossible”. We already know that it is not impossible to determine the original input from its hash value. Let’s take an example.
Suppose you are rolling a dice and the output is the hash of the number that comes up from the dice. How will you be able to determine what the original number was? It’s simple all that you have to do is to find out the hashes of all numbers from 1-6 and compare. Since hash functions are deterministic, the hash of a particular input will always be the same, so you can simply compare the hashes and find out the original input.
But this only works when the given amount of data is very less. What happens when you have a huge amount of data? Suppose you are dealing with a 128-bit hash. The only method that you have to find the original input is by using the “brute-force method”. The brute-force method basically means that you have to pick up a random input, hash it and then compare the output with the target hash and repeat until you find a match.
So, what will happen if you use this method?
- Best case scenario: You get your answer on the first try itself. You will seriously have to be the luckiest person in the world for this to happen. The odds of this happening are astronomical.
- Worst case scenario: You get your answer after 2^128 – 1 times. Basically, it means that you will find your answer at the end of all the data.
- Average scenario: You will find it somewhere in the middle so basically after 2^128/2 = 2^127 times. To put that into perspective, 2^127 = 1.7 X 10^38. In other words, it is a huge number.
So, while it is possible to break pre-image resistance via the brute force method, it takes so long that it doesn’t matter.
Property 4: Small Changes In The Input Changes the Hash.
Even if you make a small change in your input, the changes that will be reflected in the hash will be huge. Let’s test it out using SHA-256:

Do you see that? Even though you just changed the case of the first alphabet of the input, look at how much that has affected the output hash. This is a critical function because this property of hashing leads to one of the greatest qualities of the blockchain, its immutability (more on that later.)
Property 5: Collision Resistant
Given two different inputs A and B where H(A) and H(B) are their respective hashes, it is infeasible for H(A) to be equal to H(B). What that means is that for the most part, each input will have its own unique hash. Why did we say “for the most part”? Let’s talk about an interesting concept called “The Birthday Paradox”.
What is the Birthday Paradox?
If you meet any random stranger out on the streets the chances are very low for both of you to have the same birthday. In fact, assuming that all days of the year have the same likelihood of having a birthday, the chances of another person sharing your birthday is 1/365 which is 0.27%. In other words, it is really low.
However, having said that, if you gather up 20-30 people in one room, the odds of two people sharing the exact same birthday rises up astronomically. In fact, there is a 50-50 chance for 2 people sharing the same birthday in this scenario!
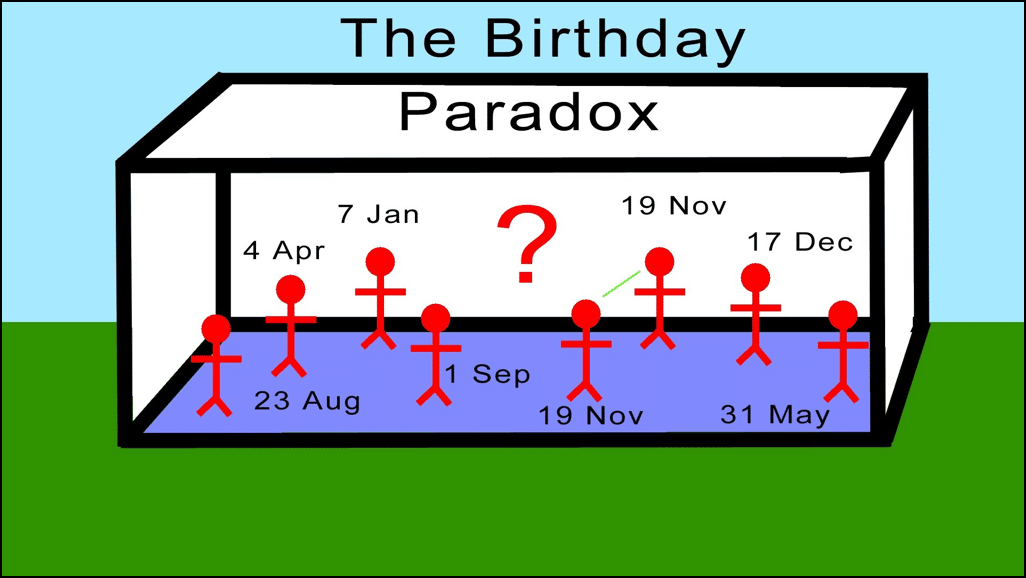
Image credit: (YouTube)
Why does that happen? It is because of a simple rule in probability which goes as follows. Suppose you have N different possibilities of an event happening, then you need square root of N random items for them to have a 50% chance of a collision.
So applying this theory for birthdays, you have 365 different possibilities of birthdays, so you just need Sqrt(365), which is ~23~, randomly chosen people for 50% chance of two people sharing birthdays.
What is the application of this in hashing?
Suppose you have a 128-bit hash which has 2^128 different possibilities. By using the birthday paradox, you have a 50% chance to break the collision resistance at the sqrt(2^128) = 2^64th instance.
As you can see, it is much easier to break collision resistance than it is to break preimage resistance. No hash function is collision free, but it usually takes so long to find a collision. So, if you are using a function like SHA-256, it is safe to assume that if H(A) = H(B) then A = B.
Property 6: Puzzle Friendly
Now, this is a fascinating property, and the application and impact that this one property has had on cryptocurrency are huge (more on that later when we cover mining and crypto puzzles). First let’s define the property, after that we will go over each term in detail.
For every output “Y”, if k is chosen from a distribution with high min-entropy it is infeasible to find an input x such that H(k|x) = Y.
That probably went all over your head! But it’s ok, let’s now understand what that definition means.
What is the meaning of “high min-entropy”?
It means that the distribution from which the value is chosen is hugely distributed so much so that us choosing a random value has a negligible probability. Basically, if you were told to chose a number between 1 and 5, that’s a low min-entropy distribution. However, if you were to choose a number between 1 and a gazillion, that is a high min-entropy distribution.
What does “k|x” mean?
The “|” denotes concatenation. Concatenation means adding two strings together. Eg. If I were to concatenate “BLUE” and “SKY” together, then the result will be “BLUESKY”.
So now let’s revisit the definition.
Suppose you have an output value “Y”. If you choose a random value “k” from a wide distribution, it is infeasible to find a value X such that the hash of the concatenation of k and x will give the output Y.
Once again, notice the word “infeasible”, it is not impossible because people do this all the time. In fact, the whole process of mining works upon this (more on that later).
Examples of cryptographic hash functions
- MD 5: It produces a 128-bit hash. Collision resistance was broken after ~2^21 hashes.
- SHA 1: Produces a 160-bit hash. Collision resistance broke after ~2^61 hashes.
- SHA 256: Produces a 256-bit hash. This is currently being used by bitcoin.
- Keccak-256: Produces a 256-bit hash and is currently used by ethereum.
Hashing and data structures
A data structure is a specialized way of storing data. There are two data structure properties that are critical if you want to understand how a blockchain works. They are:
- Pointers.
- Linked Lists.
Pointers
Pointers are variables in programming which stores the address of another variable. Usually normal variables in any programming language store data.
Eg. int a = 10, means that there is a variable “a” which stores integer values. In this case, it is storing an integer value which is 10. This is a normal variable.
Pointers, however, instead of storing values will store addresses of other variables. Which is why they are called pointers, because they are literally pointing towards the location of other variables.
Linked Lists
A linked list is one of the most important items in data structures. This is what a linked list looks like:
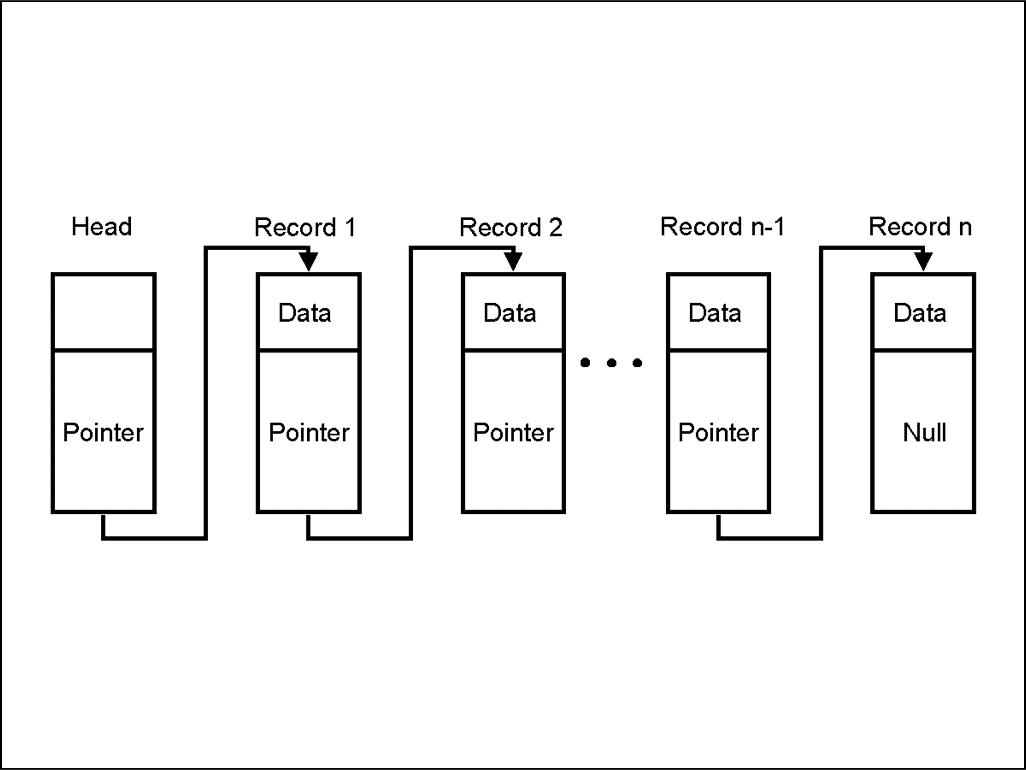
It is a sequence of blocks, each containing data that is linked to the next block via a pointer. The pointer variable, in this case, contains the address of the next node in it and hence the connection is made. The last node, as you can see, has a null pointer which means that it has no value.
One important thing to note here, the pointer inside each block contains the address of the next block. That is how the pointing is achieved. Now you might be asking what does that means for the first block in the list? Where does the pointer of the first block stay?
The first block is called the “genesis block” and its pointer lies out in the system itself. It sort of looks like this:
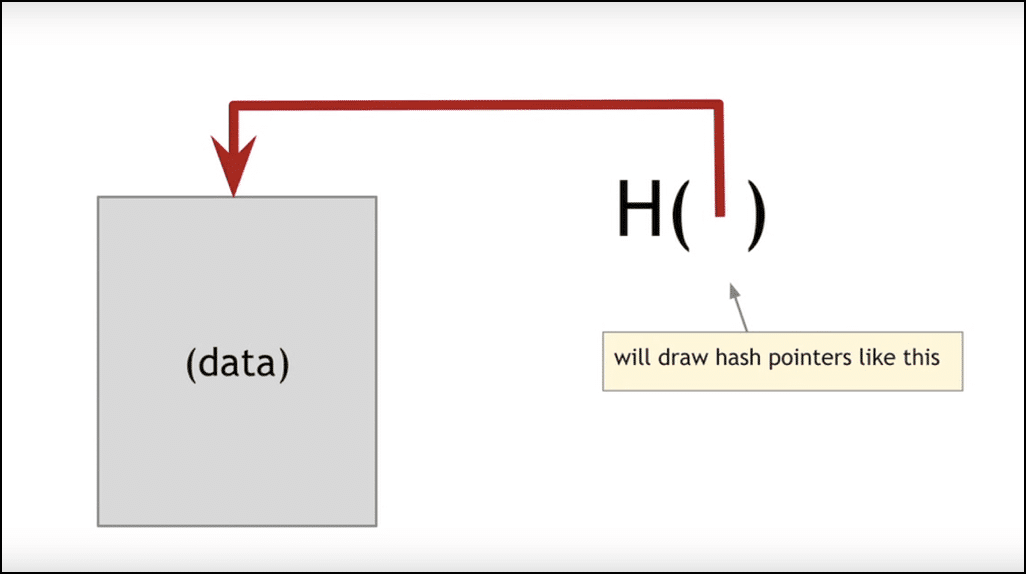
Image courtesy: Coursera
If you are wondering what the “hash pointer” means, we will get there in a bit.
As you may have guessed by now, this is what the structure of the blockchain is based on. A blockchain is basically a linked list. Let’s see what the blockchain structure looks like:
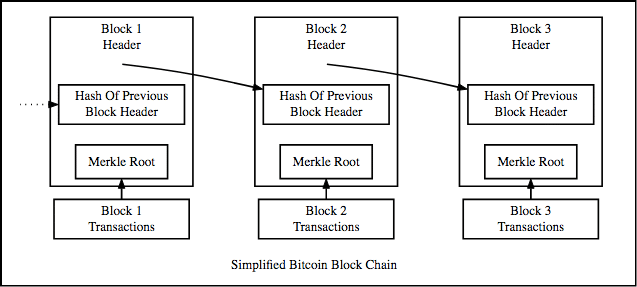
The blockchain is a linked list that contains data and a hash pointer that points to its previous block, hence creating the chain. What is a hash pointer? A hash pointer is similar to a pointer, but instead of just containing the address of the previous block it also contains the hash of the data inside the previous block. This one small tweak is what makes blockchains so amazingly reliable and trailblazing.
Imagine this for a second, a hacker attacks block 3 and tries to change the data. Because of the properties of hash functions, a slight change in data will change the hash drastically. This means that any slight changes made in block 3, will change the hash which is stored in block 2, now that in turn will change the data and the hash of block 2 which will result in changes in block 1 and so on and so forth. This will completely change the chain, which is impossible. This is exactly how blockchains attain immutability.
So what does a block header look like?
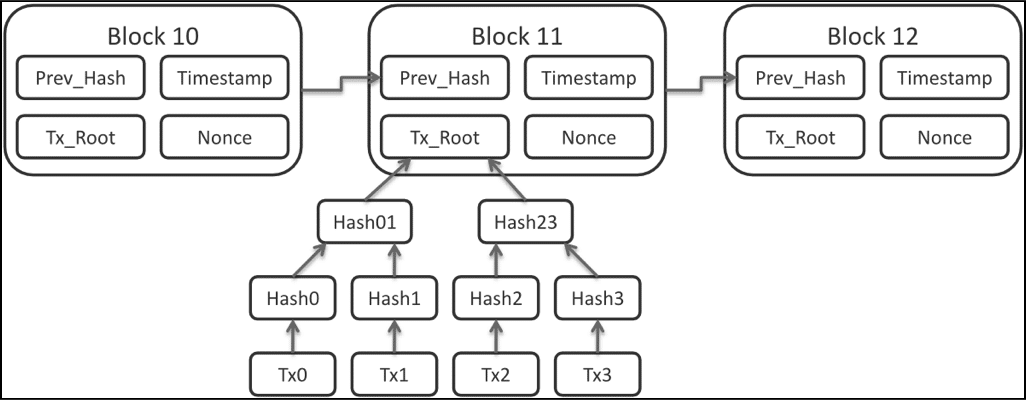
A block header contains:
- Version: The block version number.
- Time: the current timestamp.
- The current difficulty target. (More on this later).
- Hash of the previous block.
- Nonce (more on this later).
- Hash of the Merkle Root.
Right now, let’s focus on the Hash of the Merkle Root. But before that, we need to understand what a Merkle Tree is.
What is a Merkle Tree?
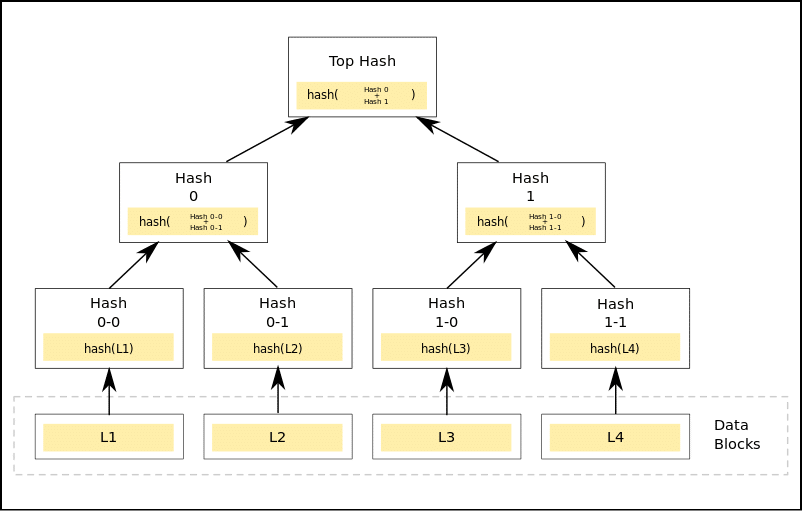
Image Courtesy: Wikipedia
The above diagram shows what a Merkle tree looks like. In a Merkle tree, each non-leaf node is the hash of the values of their child nodes.
Leaf Node: The leaf nodes are the nodes in the lowest tier of the tree. So wrt the diagram above, the leaf nodes will be L1, L2, L3 and L4.

Child Nodes: For a node, the nodes below its tier which are feeding into it are its child nodes. Wrt the diagram, the nodes labeled “Hash 0-0” and “Hash 0-1” are the child nodes of the node labeled “Hash 0”.
Root Node: The single node on the highest tier labeled “Top Hash” is the root node.
So what does a Merkle Tree have to do with blockchains?
Each block contains thousands and thousands of transactions. It will be very time inefficient to store all the data inside each block as a series. Doing so will make finding any particular transaction extremely cumbersome and time-consuming. If you use a Merkle tree, however, you will greatly cut down the time required to find out whether a particular transaction belongs in that block or not.
Let’s see this in an example. Consider the following Merkle tree:
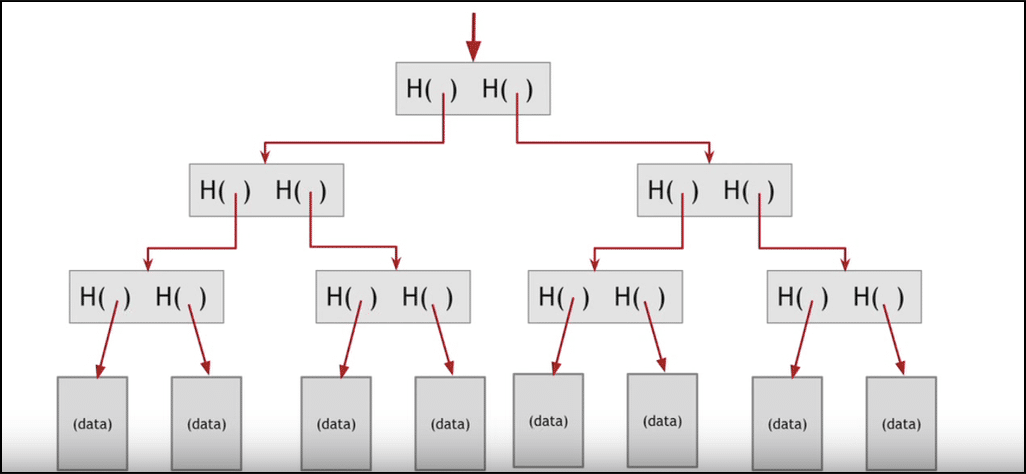
Image courtesy: Coursera
Now suppose I want to find out whether this particular data belongs in the block or not:
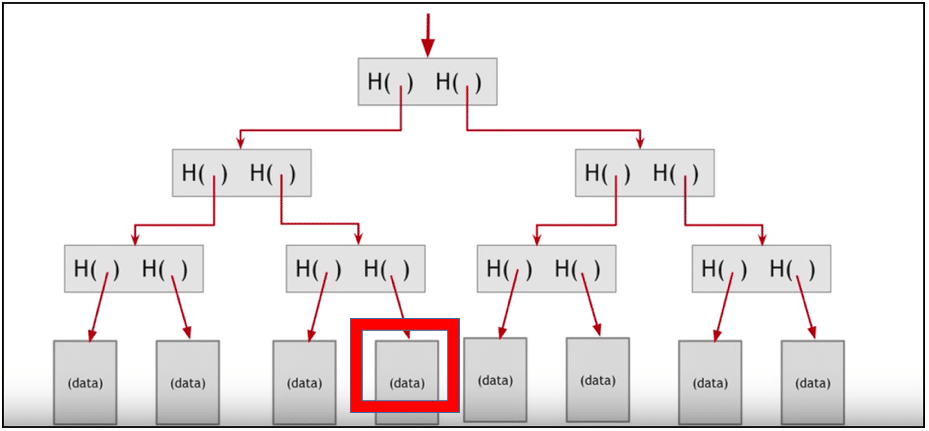
Instead of going through the cumbersome process of looking at each individual hash and seeing whether it belongs to the data or not, I can simply track it down by following the trail of hashes leading up to the data:
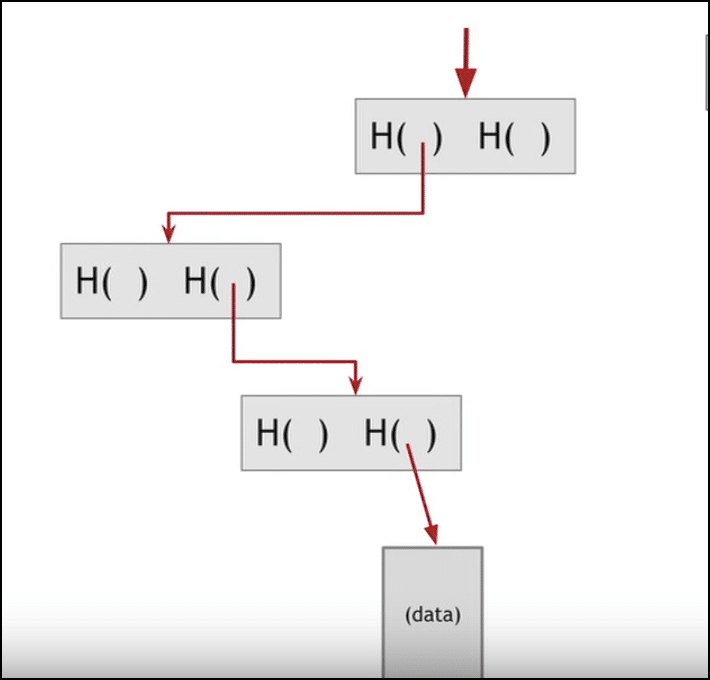
Doing this significantly reduces the time taken.
Hashing in mining: The crypto puzzles.
When we say “mining”, it basically means searching for a new block to be added in the blockchain. Miners from around the world are constantly working to make sure that the chain keeps on growing. Earlier it used to be easy for people to mine using just their laptops, but over time, people started forming mining pools to pool in their computer powers and mine more efficiently.
This, however, could have been a problem. There is a cap for each cryptocurrency, eg. for bitcoin, it is just 21 million. There are only 21 million bitcoins out there. If the miners are allowed to carry on, at this rate, they will fish out all the bitcoins in existence. On top of that, there needs to be a specific time limit in between the creation of each blocks. For bitcoin, the time limit in between block creation is 10 mins. If the blocks were allowed to be created faster, it would result in:
- More collisions: More hash functions will be generated which will inevitably cause more collisions.
- More orphaned blocks: If a lot of miners are over mining they will come up with new blocks simultaneously. This will result in or more blocks not getting to be part of the main chain and becoming orphan blocks.
So, in order to restrict block creation, a specific difficulty level is set. Mining is like a game, you solve the puzzle and you get rewards. Setting difficulty makes that puzzle much harder to solve and hence more time-consuming. WRT bitcoins the difficulty target is a 64-character string (which is the same as a SHA-256 output) which begins with a bunch of zeroes. A number of zeroes increases as the difficulty level increases. The difficulty level changes after every 2016th block.
The mining process
Note: We will primarily be talking about Bitcoin mining here.
When the bitcoin mining software wants to add a new block to the blockchain, this is the procedure it follows. Whenever a new block arrives, all the contents of the blocks are first hashed. If the hash is lesser than the difficulty target, then it is added to the blockchain and everyone in the community acknowledges the new block.
However, it is not as simple as that. You will have to be extremely lucky to get a new block just like that. This is where the nonce comes in. The nonce is an arbitrary string that is concatenated with the hash of the block. After that this concatenated string is hashed again and compared to the difficulty level. If it is not less than the difficulty level, then the nonce is changed and this keeps on repeating a million times until finally, the requirements are met. When that happens the block is added to the blockchain.
So to recap:
- The hash of the contents of the new block is taken.
- A nonce (random string) is appended to the hash.
- The new string is hashed again.
- The final hash is then compared to the difficulty level and seen whether it’s actually less than that or not.
- If not, then the nonce is changed and the process repeats again.
- If yes, then the block is added to the chain and the public ledger is updated and alerted of the addition.
- The miners responsible for this are rewarded with bitcoins.
Remember property number 6 of hash functions? The puzzle friendliness?
For every output “Y”, if k is chosen from a distribution with high min-entropy it is infeasible to find an input x such that H(k|x) = Y.
So, when it comes to bitcoin mining:
- K = Nonce
- x= the hash of the block
- Y = the difficulty target
The entire process is completely random, there is no thought process behind the selection of the nonces. It is just pure brute-force where the software keeps on randomly generating strings till they reach their goal. The entire process follows the Proof Of Work protocol which basically means:
- The puzzle-solving should be difficult.
- Checking the answer should, however, be easy for everyone. This is done to make sure that no underhanded methods were used to solve the problem.
What is hash rate?
Hash rate basically means how fast these hashing operations are taking place while mining. A high hash rate means more people and software machines are taking part in the mining process and as a result, the system is running smoothly. If the hash rate is too fast the difficulty level is increased. If the hash rate becomes too slow then the difficulty level is decreased.
Conclusion- What Is Hashing?
Hashing has truly been fundamental in the creation of blockchain technology. If one wants to understand what the blockchain is all about, they should definitely understand what hashing means.



![What Is Hashing? [Step-by-Step Guide-Under Hood Of Blockchain]](https://blockgeeks.com/wp-content/uploads/2021/09/best-bitcoin-wallets-2021.png)

![What Is Hashing? [Step-by-Step Guide-Under Hood Of Blockchain]](https://blockgeeks.com/wp-content/uploads/2021/09/cryptography-blockchain.png)
![What Is Hashing? [Step-by-Step Guide-Under Hood Of Blockchain]](https://blockgeeks.com/wp-content/uploads/2021/09/how-does-blockchain-work.png)
Well done! Great article.
I’m loving this. Great job.
Nice explanation. Would be helpful if you can provide github link to code from where you can refer to how to create blockchain from scratch.
A great follow up to the Cryptoeconomics course, building up to the block degree 😉
Q-1A: how can other miners know about the new block (new hash) added to the chain? Q-1B: how would they continue mining? Will they restart their computation to formulate/find the new block?
Q-2 How would new miners catch with advanced/older miners (would they be at the same calculation distance with older miners starting after new block is just added to the chain?
Q-3 What is better description, a new block added to the chain or a new hash added to the chain? and why please?
Suggestion for Correction in article:
“Whenever a new block arrives, all the contents of the blocks are first hashed. If the hash is lesser than the difficulty target, then it is added to the blockchain and everyone in the community acknowledges the new block”
I think you mean “If the hash is NOT Less than the difficulty target”
Great Article and thank you for it so much and looking forward your kind answers.
CORRECTION REQUIRED: First, my compliments to the author – I think the content is quite informative. Thanks. HOWEVER, you state “Imagine this for a second, a hacker attacks block 3 and tries to change the data. Because of the properties of hash functions, a slight change in data will change the hash drastically. This means that any slight changes made in block 3, will change the hash which is stored in block 2, now that in turn will change the data and the hash of block 2 which will result in changes in block 1 and so on and so forth. This will completely change the chain, which is impossible.”
Since Block 3 chronologically exists AFTER Block 2, how can a change to BLOCK 3, change Block 2? It doesn’t. [See the Bitcoin White Paper, paragraph 4. Proof-of-Work.] The whole statement should be reversed: A change to block 1 will change block 2 and a change to block 2 will change block 3… and so forth. A change to ANY block, after it is accepted into the chain, will change the blocks AFTER it, not before it.
Totally agree!
Hello BlockGeeks!
While understanding the concept of mining and miners being rewarded, I couldn’t understand the concept of miners being rewarded of creating high rate hash that any person should not be able to resolve. But can miners be trusted with the hash of data of the blocks assuming miners can be anyone.
Having said that, If miners somehow change the data(of the block added by consensus), the hash of the data will be changed and that is how the discrepancy could be detected. Is my understanding correct? Miners are actually making the hashes more secure in the block rather than “solving it”.
Hello,
Good article. As asked by Yuri earlier, how changing Block3 data changes Block2 and so on? Also, what is preventing an attacker from modifying the very last block.. In this case Block 3.. Thanks in advance
Sorry, I meant to say “… a more specific definition of “difficulty level”. I tried to edit my submission but it did not do anything when I clicked on “Edit”.
Excellent article. I would appreciate a more specific definition of “Nonce”. It was loosely correlated to the number of zeroes at the beginning of the hash, but, it was not stated that as a precise definition. How, exactly, do you compute the “difficulty level” of a hash result?
Very nice and easy to understand article.
Thanks
“Sqrt(365), which is ~23~,” How is sqrt(365) ~23~ ?
Good article, thanks!
Just notice a mistake:
“a hacker attacks block 3 and tries to change the data. Because of the properties of hash functions, a slight change in data will change the hash drastically. This means that any slight changes made in block 3, will change the hash which is stored in block 2, now that in turn will change the data and the hash of block 2 which will result in changes in block 1 and so on and so forth”
Block’s dependency should be opposite, i.e.
” … a hacker attacks block 1 … any slight changes made in block 1 … will change the hash which is stored in block 2 … which will result in changes in block 3 and so on and so forth”
https://www.youtube.com/watch?v=_160oMzblY8&t=521s
I’m agree that,thanks so much,I was confused when reading it.
I think the example to search data is wrong. MT cannot be used to speed up searching data. It is used to speed up validating data and finding the difference between two MT.
I think you are right.
“… simply track it down by following the trail of hashes leading up to the data” – I guess that practical process of validating is opposite – from data leaf to Merkle Root.
Good illustration here:
https://bitcoin.stackexchange.com/questions/50674/why-is-the-full-merkle-path-needed-to-verify-a-transaction
That’s true. Merkle tree has o(n) search complexity.
Thanks. Good text.
Thank you for explanation.
Thanks for writing, clear and understandable.
That was good. I don’t know anything about cryptography or computer science but I learnt alot from that.