
Contents
|
|
In this guide, we will dive into Centralized vs Decentralized Storage difference and look at some of the projects that are doing some great work in this space into the advantages of decentralized storage
Decentralized storage is one of the hottest blockchain use-cases in the world. Storage is the retention of retrievable data on a computer or other electronic system. In this day and age, where data is considered more valuable than money, everyone wants faster and more secure access to storage.
Contents
The evolution of the internet
In the early days of storage, file sharing was rather basic and rudimentary. If you wanted to store or share data, then you inserted a floppy disk into your CPU and transferred the data into it. Over the years, we had CDs, hard disks, which could store large quantities of data, but the core concept remained the same. You carried around a device, connected it to your computer/laptop. However, everything changed with the advent of the internet.
Thanks to the Internet, you can make connections with other computers and access pictures, data, and anything you want from anywhere on any device at any time. Think about visiting a website: in reality, you are just downloading a bunch of files that are stored somewhere on a server (most probably the server is rented by a big player). The internet initially worked on a Web 1.0 model, wherein you had to own and maintain your server. Eventually, we moved on to the “pay-as-you-use” model of Web 2.0. We starting using cloud services like S3 that provided us with scalable hosting to accommodate for traffic.
However, despite being revolutionary, there are some severe shortcomings with the current iteration of the internet that we are all familiar with.
The problems with traditional internet
#1 Censorship
As the internet currently works on a centralized model, it is susceptible to censorship. However, this is an issue that can be easily mitigated with decentralization. So, while Wikipedia might be blocked in some countries, but it can still be served via decentralized storage platforms. Similarly, a tyrannical country might suppress demonstrators to publish certain information. Demonstrators could still make a blog on a decentralized storage platform without the risk of censorship.
#2 Giving over control of data
The biggest problem of third-party cloud storage services is that the company hands over their data to a third-party for storing services. Since the data is outside the company’s control, the data privacy settings are beyond their control as well. Since users usually back up their data in real-time, they may accidentally give up control of data that they didn’t mean to share in the first place.
Also, another thing to keep in mind is that the party that you are giving control of your data are only incentivized to make profits. So they make decisions for their own benefits that may ruin your business model. Eg. Look at how changes in the Google algorithm have destroyed many internet marketing companies.
#3 Data Mismanagement
Facebook’s Cambridge Analytica debacle is the best example of a third-party mismanaging their client’s data. Aleksandr Kogan, a data scientist at Cambridge University, developed an app called “This is Your Digital Life” and then provided it to Cambridge Analytica. They, in turn, used it to survey Facebook users for academic research purposes. However, Facebook’s design allowed the app to not only collect the personal information of the users but all their connections as well. Because of this, Cambridge Analytica was able to get their hands on the personal data of a staggering 87 million Facebook users, of which 70.6 million were from the United States.
According to Facebook, the information stolen included one’s “public profile, page likes, birthday, and the current city.” Some of the users even gave them permission to access their News Feed, timeline, and messages. The data they ultimately obtained was so detailed that they were able to create psychographic profiles of the subjects of the data. The profiles created were detailed enough to suggest what kind of advertisement would be most useful to persuade a particular person in a specific location for some political event. Politicians paid Cambridge Analytica handsomely to use the information from the data breach to influence various political events.
In another infamous case, media analytics company “Deep Roots Analytics,” used the Amazon cloud server to store information about as much as 61% of the US population without password protection for almost two weeks. This information included names, email and home addresses, telephone numbers, voter ID, etc.
Centralized vs Decentralized Storage: Moving to Web 3.0
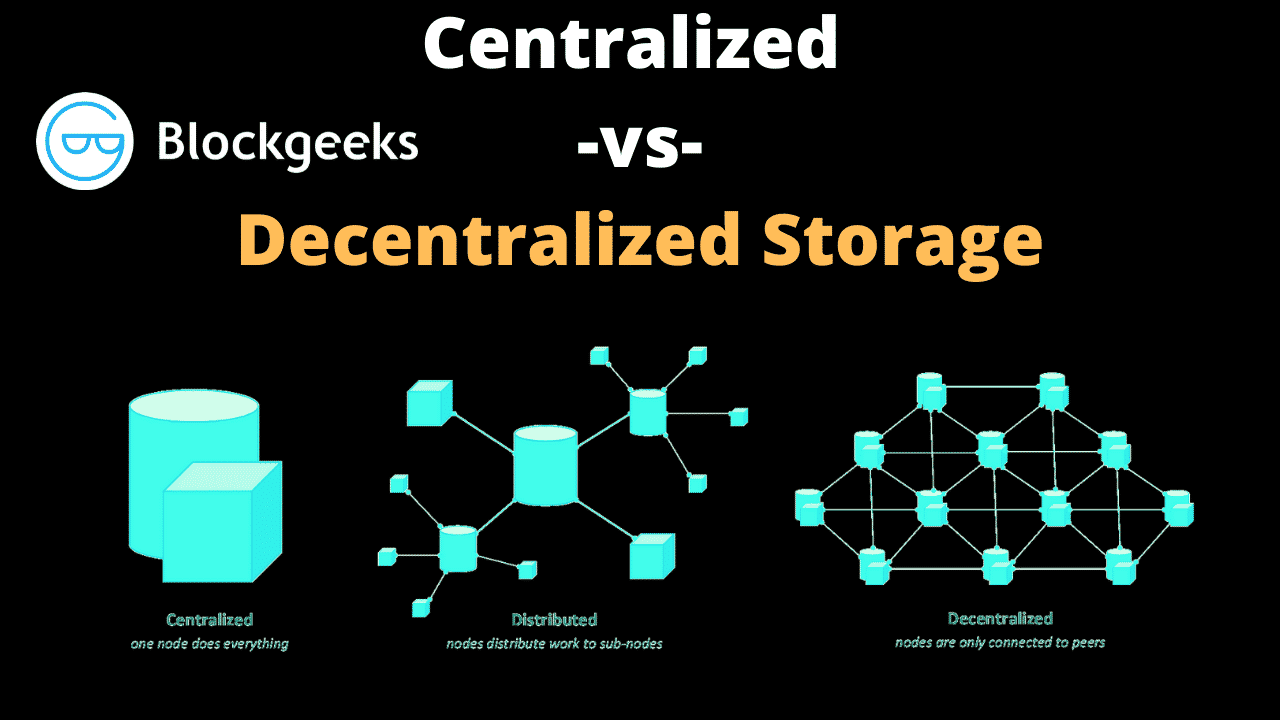
The evolution of Web 3.0 will require a decentralized distribution system of the web content rather than a centralized one. Like with conventional cloud computing, you pay as you use, instead of pre-paying for a server. However, instead of all the data being stored in a centralized server, the data is distributed into different chunks and stored inside the different nodes of a peer-to-peer (P2P) network. The ultimate goal of Web 3.0 is to provide internet service which is decentralized, censorship-resistant, and doesn’t require the user to give up control over their content.
Advantages of decentralizing storage
#1 Security
Decentralized storage platforms break apart the users’ files and distribute them across multiple nodes on their network. Since the data is scattered across multiple nodes, there is no single point of failure.
#2 Higher Liveness
In computing terms, liveness is a property with which a system will stay up and running even if certain components of it are not performing up to par. In a centralized system, if the server is down for whatever reason, the entire system goes down.
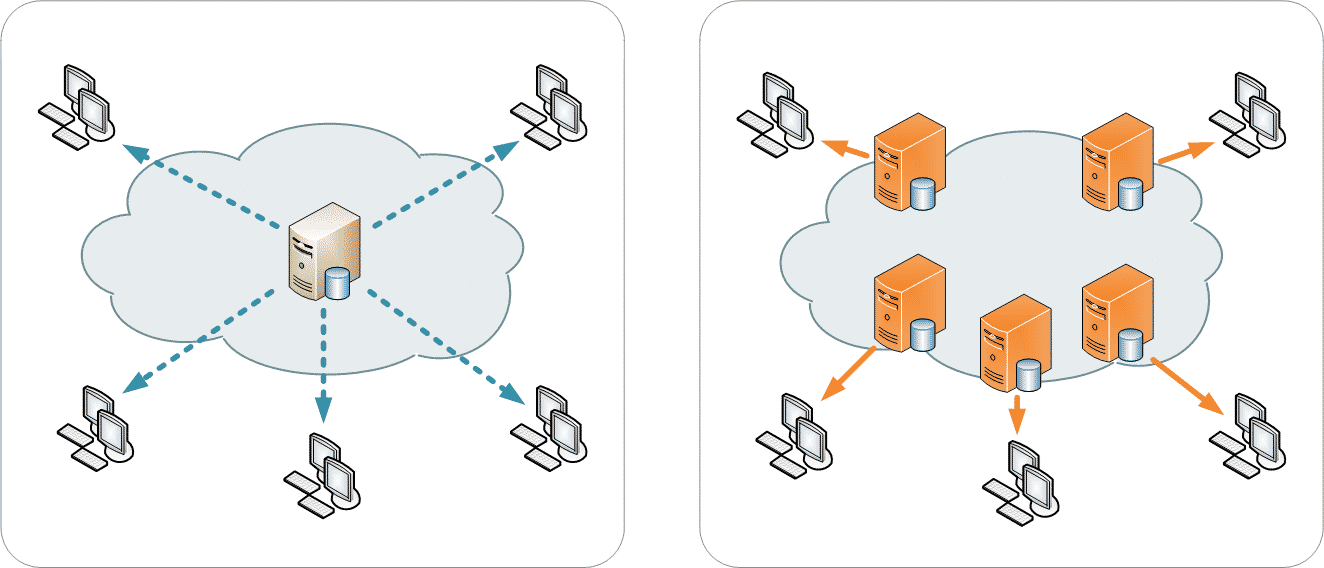
Image Credit: Wikipedia
In a decentralized system, even if one of the nodes goes down, the rest of the network will be more than capable of making up for the slack.
RIF Storage

Rootstock (RSK) is a smart contract platform that is connected to Bitcoin’s blockchain through sidechain technology. It has a technology stack called Rootstock Infrastructure Framework Open Standard or “RIFOS.” One can think of RIFOS as a third layer on top of the Bitcoin blockchain since it is constructed on top of a side chain (RSK) that is existing on top of Bitcoin. RIFOS is currently working on multiple projects, including a storage application called “RIF Storage.”
Keep in mind the following features when it comes to RIFOS:
- As long as a product is compatible with the underlying protocols, developers can seamlessly integrate it within the RIFOS ecosystem.
- All the individual components of RIFOS have been designed to maximize the potential benefits for those who want to offer their infrastructure services within the protocol’s ecosystem.
- All the components are protected by the security provided by the Bitcoin Network.
- Its protocols will include mechanisms to trigger network effects and economies of scale.
- Most of the services running in RIFOS will be consumed utilizing a single token (RIF).
One of the areas where RIFOS is currently working on is “payments” with its Lumino project.
RIF Storage allows the following:
https://www.rifos.org/blog/rif-storage-a-decentralized-storage-solution
- Allow for the encrypted and decentralized storage and streaming of information via its unified interface and set of libraries.
- Offers multiple options for different needs, from decentralized swarm storage to encrypted cloud and physical storage.
Through RIF Storage you will gain access to several storage systems like IPFS and Swarm. Let’s explore the partnership between RIF Storage and Swarm.
RIF Storage partnership with Swarm
RIFOS entered into a partnership with Swarm network, a distributed storage platform and content distribution service, to create a truly decentralized and unstoppable Internet of Value.
The partnership between Swarm and RIF storage will also take care of:
- Create a solid incentivization plan which combines Swarm´s Accounting Protocol (SWAP) with a layer-2 (L2) settlement and payment mechanism.
- Build the required accounting functionalities between nodes for provided data and settling.
- Add interoperability and antifragility to allow Swarm to become a multi-blockchain decentralized storage implementation.
This partnership will be split into the following three phases:
- Phase 1: This phase is launching soon on testnet and incentivizes fair use of the network between the peers by paying them for downloading content. The payment will be done off-chain.
- Phase 2: This phase will add spam protection by making uploading content optionally paid similar to how you can choose to pay transaction fees in the Bitcoin network.
- Phase 3: The final phase will provide decentralized persistence and market-driven prices.
More insight into how RIF Storage works with Swarm
There are only two things that users will do with cloud storage – upload and download files. When it comes to Swarm, this is how uploading will work:
- Uploading the file to a node.
- Preparing the file (chunking and encrypting).
- Distributing the chunks to the network.
To upload a file, the user first connects to a Swarm node and uploads a file through a user interface as the RIF Storage UI. Before uploading to the network, the file is split into small parts called “chunks.” The chunks are then mapped into a Merkle Tree:
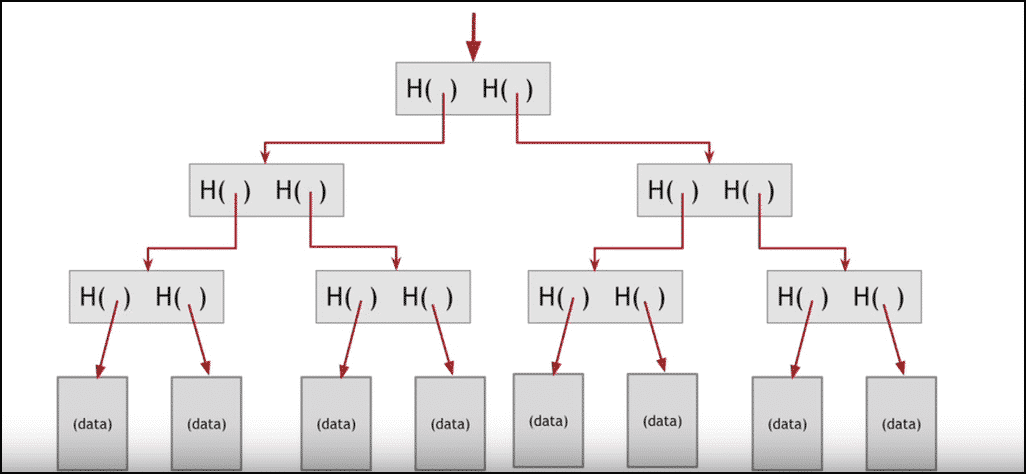
In this tree, the leaves are populated by the hash of each chunk, while the root of the tree represents the hash of the whole file. Do you want to learn more about Merkle Trees? You can read our guide here.
The downloading process works in the reverse order. The user requests a file by the root hash of the Merkle tree. The chunks are eventually decrypted and the file assembled.
Incentivizing the network
For incentivizing individual nodes to take part in the system, Swarm defined a system called Swarm Accounting Protocol (SWAP). According to their documentation, SWAP is a “tit-for-tat system where nodes account how much data they request and serve. Basically, this means that if you request a million chunks from me, I will serve you one million chunks in return.”
Once one of these nodes reaches a certain threshold ( ~10 MB right now), it will automatically send “cheques” for payment purposes. The nodes are incentivized to pay their debts on time. Otherwise, they risk getting disconnected from the network. From an economic perspective, getting back into the network is a lot more expensive than paying the debt.
Siacoin

Sia is a blockchain-based, cloud platform that aims to provide a solution for decentralized storage. Peers on Sia’s network can rent hard drive space from one another, for storage purposes instead of renting it from a centralized provider. Not only does this decentralized approach makes Sia more secure, but it drastically reduces the overall cost as well. Simply put, if you have unused space on your hard drive, then you will be able to rent it in Sia and earn money from it, in the form of Siacoins (SC). Sia uses a dual token system – Siacoin and Siafunds.
The creative forces behind Sia are David Vorick and Luke Champine of Nebulous Inc, a VC-funded startup in Boston.
How does the Sia P2P storage work?
There are two main components in Sia’s ecosystem – the renters and the hosts. The renters can pay hosts in Siacoin to lease storage capacities. They are also free to determine the storage fees directly from the hosts.
Since the hosts play such a vital role in the network, they have the freedom to:
- Promote their storage resources and the quality of service that they provide.
- Have the right to refuse rent storage to a particular client if they feel that the data is too sensitive, ethically unacceptable, or illegal.
The renters, for their part, have the right to:
- Protect the flies by splitting them up and having them copied between various hosts. This will help ensure the safety of the file.
- Pay the hosts more than the asked fees to ensure preferential treatment, such as faster upload speeds and granting storage requests.
Uploading and Downloading Files
As long as funds remain in the allowance, renters can upload and download their files as many times as they want. The current contracts will not be affected if the host decides to change their pricing mid-operation. Regarding data transfer:
- Done by direct connection between the renter and the hosts.
- The Twofish algorithm encrypts data and stored with the redundancy algorithm Reed-Solomon among the hosts.
Storj

Storj is a decentralized storage project that’s been built on Ethereum. In a short time, they have built quite a healthy community. It has been described as a platform, cryptocurrency, and suite of decentralized applications that allows you to store data in a secure and decentralized manner by using encryption, sharding, and a blockchain-based hash table.
Storj and torrents
Torrents use a peer-to-peer network, which works like this:
- Many users keep a copy of the same file. These users are called “peers.”
- When someone wants a copy of the file, they send a request to the torrent network.
- The peers who have the file will send fragments of it to the person requesting it.
- When you download a file from torrent, you download multiple fragments of the same file from different sources. This simple innovation makes downloading a lot faster.
The key thing to note in this entire process is that there is no central entity controlling the torrents. So even if one of the peers sharing the file goes down, you can still download the file. Storj works in a pretty similar way.
Storj uses a method called “sharding” to fragment the files. You can learn more about sharding in this guide here. Any file stored in the Storj network will be fragmented into shards and shared between the users in the network. Anytime a user wants a file, Storj pieces together its shards by using distributed hash tables.
Conclusion: Centralized vs Decentralized Storage
Decentralized storage can become a critical part of a company’s daily operations. Blockchain integration might very well become the catalyst needed to boost storage to the next level. Currently, the projects mentioned above are doing fantastic work in this regard. With mainstream acceptance and usage, it will be fascinating to see how this space evolves in the future.






Sounds like the days of napster are back, thank God.