
Contents
|
|
In this guide, you will learn What are ethereum Nodes And Sharding. If you’d like to learn even more, please take a look at our blockchain courses.
If you have been active in one form or another in cryptocurrency for the last year then you would know that there has been one issue which has plagued both bitcoin and Ethereum: Scalability.
Bitcoin has somewhat addressed this issue by activating Segwit and by hard forking into Bitcoin Cash. Ethereum, however, is trying to solve this issue in a different way. One of the many protocols that they are looking to activate, as they go into the next phase of their growth, is “sharding”. Before we understand what that means, we need to have a thorough understanding of networks and nodes.
 ethereum Nodes And Sharding?” width=”1200″ height=”628″ />
ethereum Nodes And Sharding?” width=”1200″ height=”628″ />
What are Ethereum Nodes And Sharding?
What are nodes, networks, and parameters?
Let’s understand what the concept means by using simple day-to-day activities.
(Before we begin, credit to 3dBuzz for the wonderful explanation.)
Think of a box:
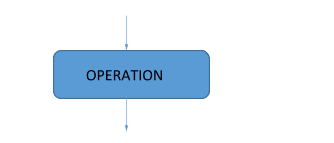
This box takes in inputs, performs some sort of operations on them, and then gives an output. This box is a “node”. Keep in mind, nodes are not exactly “boxes”, we are just using a hypothetical case here.
A network is a collection of these nodes which are interlinked to one another.
Parameters are the rules that the nodes are bound by.
That, in essence, is what nodes and networks are. Now let’s check out some simple day-to-day activities explained via nodes and networks.
Let’s see how a simple paper shredder works.
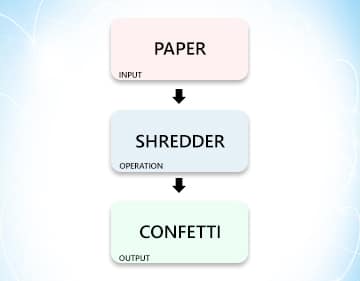
So, what happened here?
You are using three nodes: The paper the shredder and the….well…” shredded stuff”. These three nodes make up the “Shredding network”. Let’s have some more fun with this. Till now, we have assumed that nodes take in only one input. What if they take more than that?
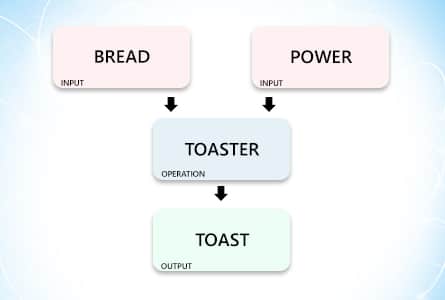
Let’s take the example of a toaster. A toaster takes in two inputs:
- Electricity
- Bread
So this is what it will look like:
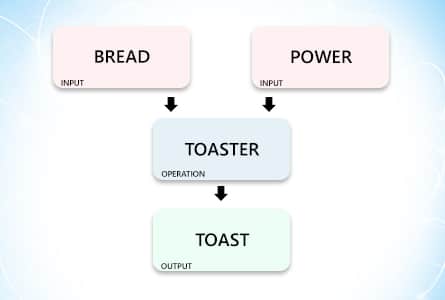
Remember one thing, a toaster can’t work if even one of its inputs is missing.
Now, it’s time to take it up another notch.
Let’s think of a complex network, which uses parameters. Think of your television set. Your television set is connected to your service provider. Suppose you own a PS4, and because you suck at making decisions, you own an Xbox as well.
So, if we were to map out the whole “TV network”, this is what it would look like:
Uh, oh.. we have a problem here.
You can only access one of those nodes via your TV. You can’t really watch Game of Thrones and play Uncharted at the same time now, can you? So, how are you going to make sure that your TV can access only one node at a time? This is where you introduce the parameters. The parameters are what make your nodes unique. Suppose, you want to add a parameter to the television called “Channel Switcher”. And this is what the channel switcher works like:
- If you press “0” then it will show normal TV aka service provider.
- If you press “1” then you will be able to access PS4.
- If you press “2” then you will be able to access Xbox.
Just by the addition of these parameters you made your node i.e. the television unique. So, let’s explore what other parameters we can give our television to make it more unique:
- Size: Say, our television is a 55-inch screen.
- Colour: Our TV is silvery grey in colour.
- Brand: We have a Sony TV.
- Type: We have a plasma screen.
Ok, so now thanks to our parameters, we have a television which is more well defined. Now we know that we have a 55 inch, silvery grey, plasma screen Sony TV.
So, from everything that we have learned so far, let’s try to define what nodes, network and parameters mean.
- Nodes: Individual components which take in input and performs a function on them and gives out an output.
- Network: Collection of nodes which are interconnected to one another.
- Parameters: Rules that define a node and make it more unique
Nodes and Network in the context of telecommunications
Our entire telecommunications system works on the basis of networks and nodes. Your internet, calls, SMSs, every single one of those work because of carefully laid out networks and nodes. So, how do you define a telecom network? According to Encyclopedia Britannica,
“Telecom network is an electronic system of links and switches, and the controls that govern their operation, that allows for data transfer and exchange among multiple users.”
Why do we need a telecommunications network?
While it is possible to make one-to-one connections between individual people, it will be extremely expensive and cumbersome. Plus, it will be an extremely ineffective process because most of the communication lines will be idle and under/not utilized.
To make this process more efficient, we use a telecommunications network. So, what is the definition of a node in this context?
In this context, the node is either a redistribution point or a communications end-point.
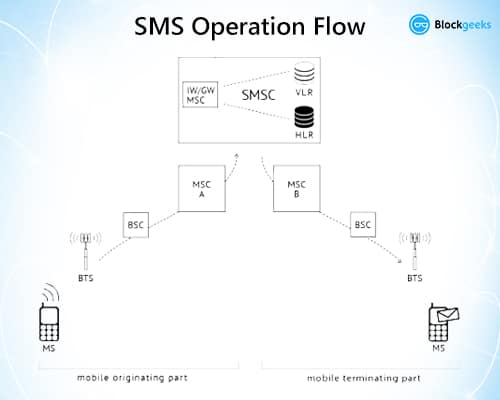
So, let’s see an example of how this works. Consider a simple GSM network. Suppose, Alice wants to send an SMS to Bob, how will the entire system work? (Shoutout to Roviell YouTube channel for the explanation).
- Step 1: Alice writes the message and presses send. The message goes to the Base Station aka BST. The BST connects you to the network. There are tons of BSTs around. Think of them as waiters in a restaurant. You simply raise your hand (send an SMS) and you get their attention.
- Step 2: The Base Station Controller aka BSC makes sure that the BSTs are all in order and that everything is in working condition. Using our restaurant analogy, the BSC is the “maître d’hôtel” or the head waiter who makes sure that each table is been attended to by waiters. (Remember Jean Phillippe from Hell’s Kitchen? Yeah, that guy.)
- Step 3: From the BSC the message now goes to the Mobile Switching Center aka MSC. It makes sure that the data moves seamlessly from the stations to the networks and vice-versa. In our restaurant analogy, the MSC are the head chefs, who take the orders and relay them to the chefs AND also put the finishing touches on the dishes before sending them out.
- Step 4: Now the message gets sent to the Short Message Service Center aka SMSC. These are the chefs in the analogy. Over here, the message is saved until they get more information about the recipient. The SMSC gets help from sources like the Home Location Register (HLR) and the Visitor Location Register (VLR), these 2 are databases which contain all the information about the network. They basically help track down the sender AND the recipient to see if the message can be sent. They check whether the recipient’s phone is switched off, or if it is out of coverage area etc. If for some reason the message can’t be sent, then it gets stored in the SMSC for a maximum of 6 hours before it gets deleted.
- Step 5: Now, if the SMS is good to go, the SMSC hands the message over to the recipient’s MSC.
- Step 6: The SMS goes to the BSC.
- Step 7: The BSC forwards the message to the BST.
- Step 8: The BST then finally sends the message to the recipient.
So, this is an overview of how the entire SMS system works. The BSC, BST, MSC, SMSC, HLR and VLR are all nodes in the GSM network. This is what the whole thing looks like:
What is a Peer-to-Peer Network?
A normal network structure is the “client-server” structure.
How does that work?
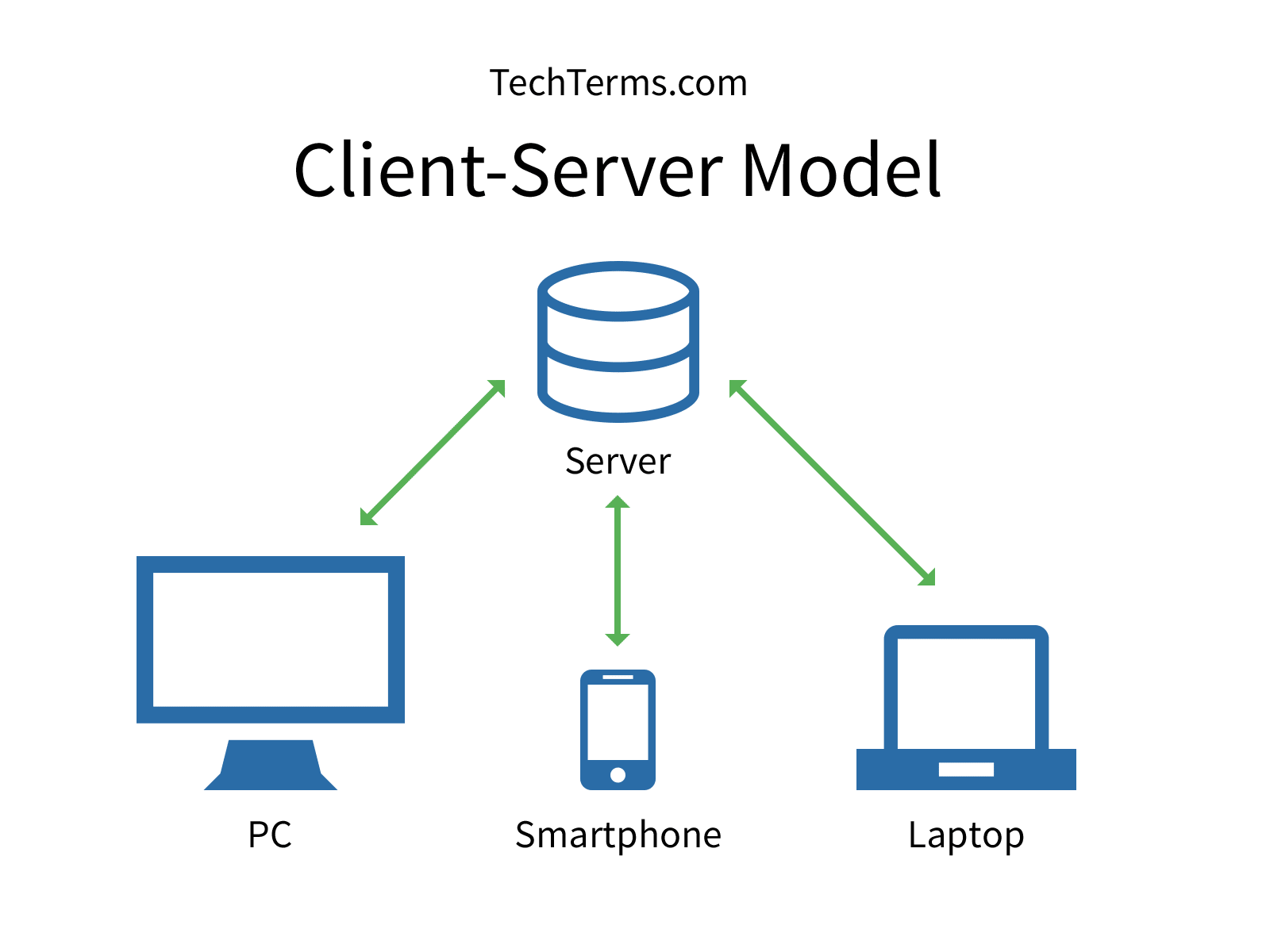
There is a centralized server. And everyone who wants to connect with the server can send a query to get the required information. This is pretty much how the internet works. When you want to Google something, you send a query to the Google server, which comes back with the required results. So, this is a client-server system. Now, what is the problem with this model?
Since everything is dependent on the server, it is critical for the server to be functioning at all times for the system to work. It is a bottleneck. Now suppose, for whatever reason the main server stops working, everyone in the network will be affected. Plus, there are also security concerns. Since the network is centralized, the server itself handles a lot of sensitive information regarding the clients. This means that anyone can hack the server and get those pieces of information. Plus, there is also the issue of censorship. What if the server decides that a particular item (movie, song, book etc.) is not agreeable and decides not to propagate it in their network?
So, to counter all these issues, a different kind of network architecture came about. It is a network which partitions its entire workload between participants, who are all equally privileged, called “peers”. There is no longer one central server, now there are several distributed and decentralized peers. This is a peer-to-peer network.
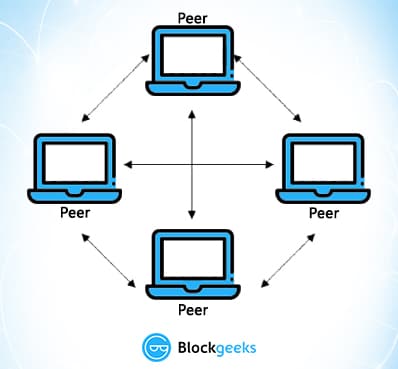
Image Courtesy: InfoZones
Why do people use the peer-to-peer network?
One of the main uses of the peer-to-peer network is file sharing, also called torrenting. If you are to use a client-server model for downloading, then it is usually extremely slow and entirely dependent on the health of the server. Plus, like we said, it is prone to censorship.
However, in a peer-to-peer system, there is no central authority, and hence if even one of the peers in the network goes out of the race, you still have more peers to download from. Plus, it is not subject to the idealistic standards of a central system, hence it is not prone to censorship
If we were to compare the two:
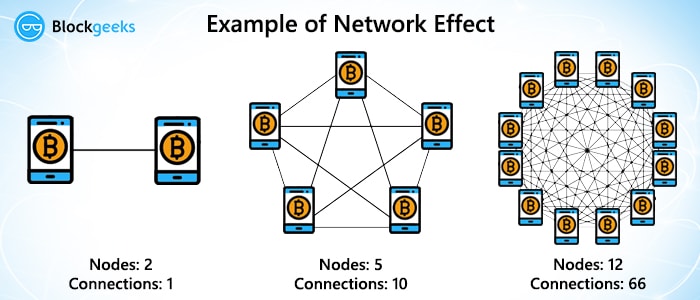
Image courtesy: Quora
The decentralized nature of a peer-to-peer system becomes critical as we move on to the next section. How critical? Well, the simple (at least on paper) idea of combining this peer-to-peer network with a payment system has completely revolutionized the finance industry by giving birth to cryptocurrency.
The use of networks and nodes in cryptocurrencies.
Let’s take a look at Ethereum’s network structure.
Ethereum is structured as a peer-to-peer network, such that the participants aka the peers aka the nodes are not given any extra special privileges. The idea is to create an egalitarian network. The nodes are not given any special privileges, however, their functions and degree of participation may differ. There is no centralized server/entity, nor is there any hierarchy. It is a flat topology.
All decentralized cryptocurrencies are structured like that is because of a simple reason, to stay true to their philosophy. The idea is to have a currency system, where everyone is treated as an equal and there is no governing body, which can determine the value of the currency based on a whim. This is true for both bitcoin and ethereum.
Now, if there is no central system, how would everyone in the system get to know that a certain transaction has happened? The network follows the gossip protocol. Think of how gossip spreads. Suppose Alice sent 3 ETH to Bob. The nodes nearest to her will get to know of this, and then they will tell the nodes closest to them, and then they will tell their neighbors, and this will keep on spreading out until everyone knows. Nodes are basically your nosy, annoying relatives.
So, what is a node in the context of ethereum? A node is simply a computer that participates in the ethereum network. This participation can be in three ways
- By keeping a shallow-copy of the blockchain aka a Light Client
- By keeping a full-copy of the blockchain aka a Full Node
- By verifying the transactions aka Mining
What is a Light Client?
As we have mentioned before, the idea of a peer-to-peer system is to distribute network responsibilities among nodes called “peers”. No preference is given to any one of them. However, what about people who want to take part in the network but don’t have the system resources to download and maintain the full blockchain in their system? They can choose to become “Light clients”. By being a Light Client, they get high-security assurances about certain states of ethereum and also the power to verify the execution of a transaction.
What is a Full Node?
Any computer, connected to the ethereum network, which fully enforces all the consensus rules of ethereum is called a Full Node. A full node downloads the entire blockchain in the user’s desktop. Full nodes form the backbone of the ethereum system and keep the entire network honest. Some of the consensus rules that full nodes enforce are:
- Making sure that the correct block reward is given out for each block mined (5 ETH)
- Transactions have the correct signatures
- Transactions and blocks are in the correct data format
- No double spending is occurring in any of the blocks
The full nodes basically validate the nodes and transactions and relay the information to the other nodes (using the gossip protocol).
Miners vs Nodes
To keep it simple, all miners are full nodes, but not all full nodes are miners. Miners need to be running full nodes to access the blockchain. Anyone who runs a full node need not mine for blocks.
What is the scalability problem that ethereum is facing?
How does consensus happen in the Ethereum network? Each and every node in the network does every calculation, and when they all come to a consensus, the transaction is deemed good. Now, this might have worked properly, in the beginning, however, ethereum has grown very popular and the number of transactions has been steadily increasing. Check out this graph by Etherscan:
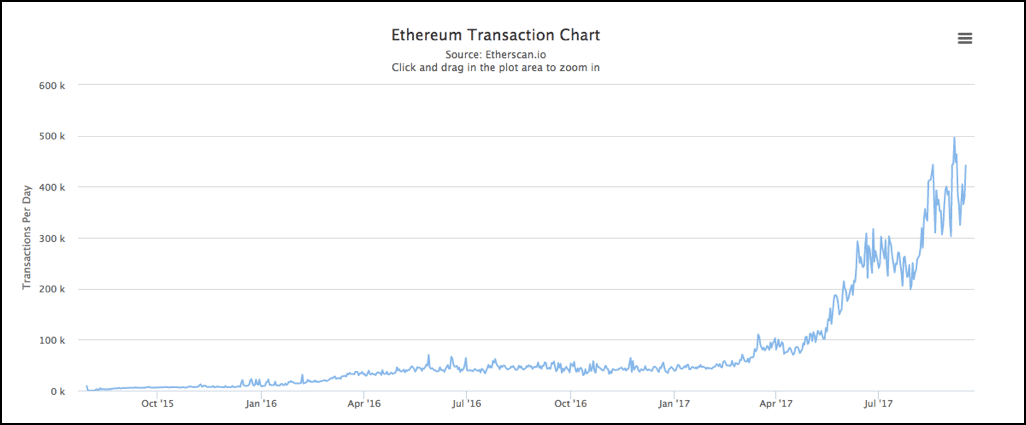
Image Courtesy: Etherscan
Now, even though this is a good thing, the number of calculations that the networks have to go through before they can come to a consensus has increased exponentially as a result. Along with that, there is another problem that has come up. ethereum has seen widespread adoption because of the backing by certain corporate heavyweights and the popularity of its ICOs. As a result of this, the number of nodes on the ethereum network has increased exponentially. In fact, it is the cryptocurrency with the most nodes and hence most decentralized.
In fact, as of May 2017, ethereum had 25,000 nodes as compared to Bitcoin’s 7000!! That’s more than 3 times. In fact, the number of nodes from April to May increase by 81%…that’s nearly double!
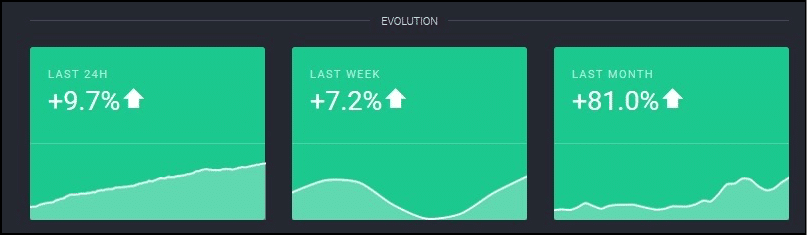
Image Courtesy: Trust Nodes.
Now, you may be thinking that having more nodes in the network will help speed up the transaction time. Well… think again.
Consensus happens in a linear manner. Meaning, suppose there are 3 nodes A, B and C.
For consensus to occur, first A would do the calculations and verify and then B will do the same and then C.
However, if there is a new node in the system called “D”, that would add one more node to the consensus system, which will increase the overall time period. As ethereum has become more popular, the transaction times have gotten slower.
In fact, in a speed test, it was seen that ethereum managed a paltry 20 transactions per second as compared to PayPal’s 193 and Visa’s 1667!!
Now remember one thing, ethereum doesn’t envision themselves to be just mere currency, their ultimate vision is to be something like the new internet. They want people to create DApps on the scale of Facebook and Youtube to run on top of their blockchain. In order for something like this to happen, they will need to do something about their scalability issues.
In order to address that, three proposals were raised:
- Increase the block size
- Make users use different alt coins
- Sharding
Increase the block size
So, one solution is to increase the block size. While this would definitely improve the performance by increasing the number of transactions going into one block, there are several problems that can happen as a result:
- Firstly, this will still not solve the problem of nodes coming to a consensus at a slower pace. In fact, as the number of transactions per block increases, the number of calculations and verifications per node will increase as well.
- In order to accommodate for more and more transactions, the block sizes need to be increased periodically. This will centralize the system more because normal computers and users won’t be able to download and preserve such bulky blockchains. This goes against the egalitarian spirit of a blockchain.
- Finally, block size increase will happen only via hardfork, which can split the community. The last time a major hardfork happened in ethereum the entire community was divided and two separate currencies came about. People don’t really want this to happen again.
Make users use different altcoins.
Another proposal was to run parallel blockchains instead of one main blockchain. Basically, instead of making 50 DApps run on one main blockchain, have 2 blockchains and run 25 DApps each. There were two problems with this proposal:
- It is not wise to split up the hashrate of a chain. The hashrate of the chain after all determines how secure it is from external hackers and fast the system is.
- It will be easier for malicious miners to get 51% majority on the smaller chains.
Sharding
Finally, sharding was decided as the way to go for ethereum. Before we do a deep dive into sharding let’s gain a simple understanding as to what it means. Suppose there are three nodes A, B and C and they have to verify data T. Instead of A, B and C verifying the entire data T individually, the data will be broken into 3 shards: T1, T2 and T3. After that A, B and C will verify one shard each side-by-side. As you can see the amount of time you are saving is exponential.
Anyway, let’s do a deep dive!
What is sharding?
Sharding is a term that has been taken from database systems. Let’s see what sharding means with respect to the database. Suppose you have a huge bulky database for your website. Having a bulky database not only makes searching for data slower, but it also hinders your scalability. So, what do you do in this case?
What if you do a horizontal partition on your data and turn them into smaller tables and store them on different database servers?
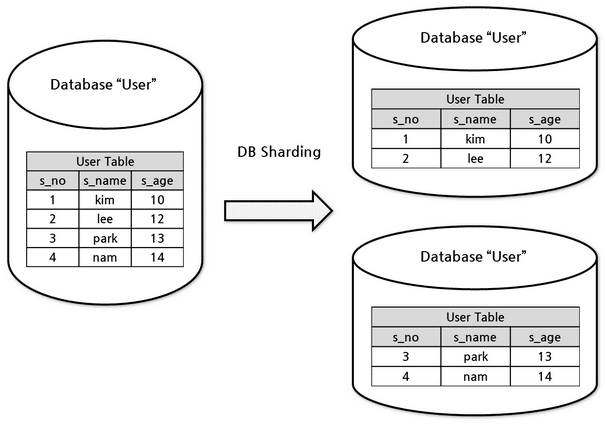
Image courtesy: Dzone
Like so?
Now, you might be asking, why a horizontal partition and not a vertical partition? That is because of the way tables are designed:

You see? It is the same table/database but with lesser data. These smaller databases are known as shards of the larger database. Each shard should be identical with the same table structure.
Sharding in the context of blockchain
Now, as we have seen, the problem with Ethereum consensus is that all the nodes need to do all the calculations and verifications for each and every transaction. This makes the whole process very slow and cumbersome. So, how is sharding going to help this?
Consider the state of the ethereum blockchain which we shall call “Global State”, which is visible to everyone. Let’s consider the Merkle Root of this global state. (For Merkle trees and roots read our article on HASHING). This state root is going to be broken up into shard roots and each of these shared roots is going to have their own state. These states are going to be represented in the form of a Merkle tree.
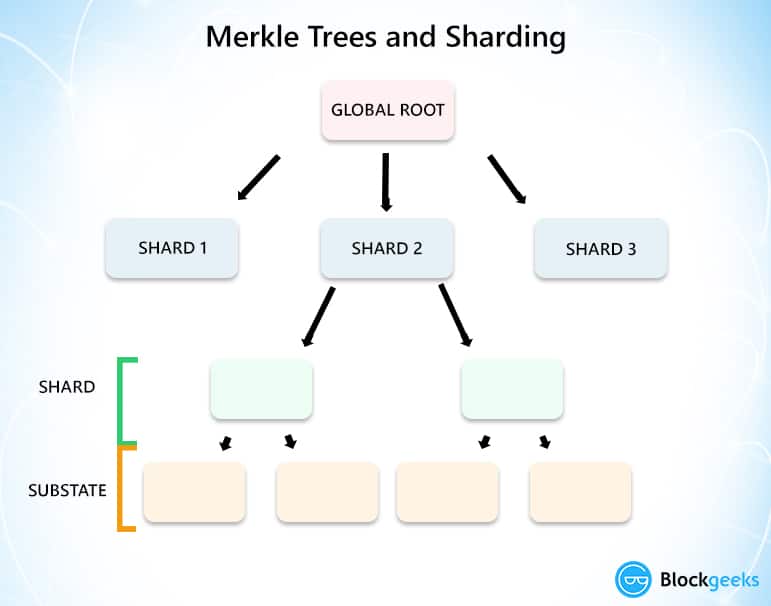
This is a very simple structure of what that is supposed to look like.
Now, let’s get into the internal mechanics.
So what happens what after sharding is activated?
- The state is split into shards
- Each unique account is in one shard
- Accounts can only transact with other accounts in the same shard
In Devcon, Vitalik Buterin explained shards like this:
Imagine that ethereum has been split into thousands of islands. Each island can do its own thing. Each of the island has its own unique features and everyone belonging on that island i.e. the accounts, can interact with each other AND they can freely indulge in all its features. If they want to contact with other islands, they will have to use some sort of protocol.
So, the question is, how is that going to change the blockchain?
What does a normal block in bitcoin or ethereum (pre-sharding) look like?

So, there is a block header and the body which contains all the transactions in the block. The Merkle root of all the transactions will be in the block header.
Now, think about this. Did bitcoin really need blocks? Did it really need a blockchain? Satoshi could have simply made a chain of transactions by including the hash of the previous transaction in the newer transaction, making a “transaction chain” so to speak.
The reason why they arrange these transactions in a block is to create one level of interaction and make the whole process more scalable. What ethereum suggests is that they change this into two levels of interaction.
The First Level
The first level is the transaction group. Each shard has its own group of a transaction.
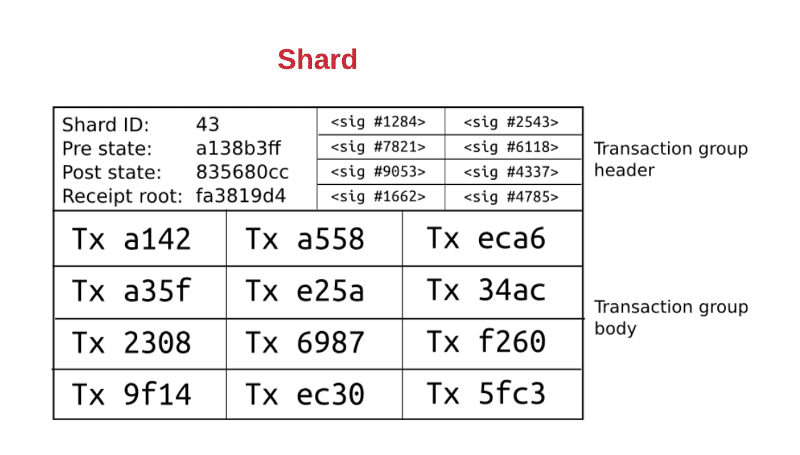
Image courtesy: Hackernoon
The transaction group is divided into the transaction group header and the transaction group body.
Transaction Group Header
The header is divided into distinct left and right parts.
The Left Part:
- Shard ID: The ID of the shard that the transaction group belongs to.
- Pre-state root: This the state of the root of shard 43 before the transactions were applied.
- Post state root: This is the state of the root of shard 43 after the transactions are applied.
- Receipt root: The receipt root after all the transactions in shard 43 are applied.
The Right Part:
The right part is full of random validators who need to verify the transactions in the shard itself. They are all randomly chosen.
Transaction Group Body
It has all the transaction IDs in the shard itself.
Properties of Level One
- Every transaction specifies the ID of the shard it belongs to.
- A transaction belonging to a particular shard shows that it has occurred between two accounts which are native to that particular shard.
- Transaction group has transactions which belong to only that shard ID and are unique to it.
- Specifies the pre and post state root.
Now, let’s look at the top level aka the second level.
The Second Level
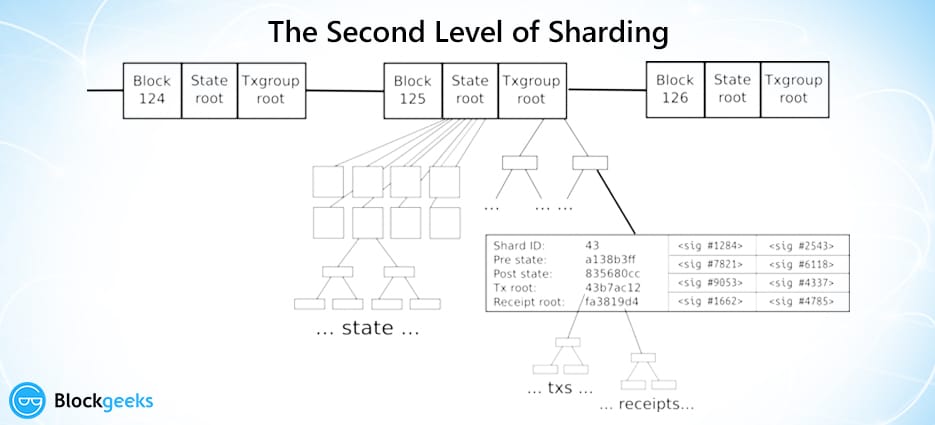
Image courtesy: Hackernoon.
Don’t be scared! It is easier to understand than it looks.
There is the normal blockchain, but now it contains two primary roots:
- The state root
- The transaction group root
The state root represents the entire state, and as we have seen before, the state is broken down into shards, which contain their own substates.
The transaction group root contains all the transaction groups inside that particular block.
Properties Of Level Two
- Level two is like a simple blockchain, which accepts transaction groups rather than transactions.
- Transaction group is valid only if:a) Pre-state root matches the shard root in the global state.
b) The signatures in the transaction group are all validated. - If the transaction group gets in, then the global state root becomes the post-state root of that particular shard ID.
So how does cross-shard communication happen?
Now, remember our island analogy?
The shards are basically like islands. So how do these islands communicate with each other? Remember, the purpose of shards is to make lots of parallel transactions happen at the same time to increase performance. If ethereum allows random cross-shard communication, then that defeats the entire purpose of sharding.
So what protocol needs to be followed for cross-shard communication?
ethereum chose to follow the receipt paradigm for cross-shard communications. Check this out:
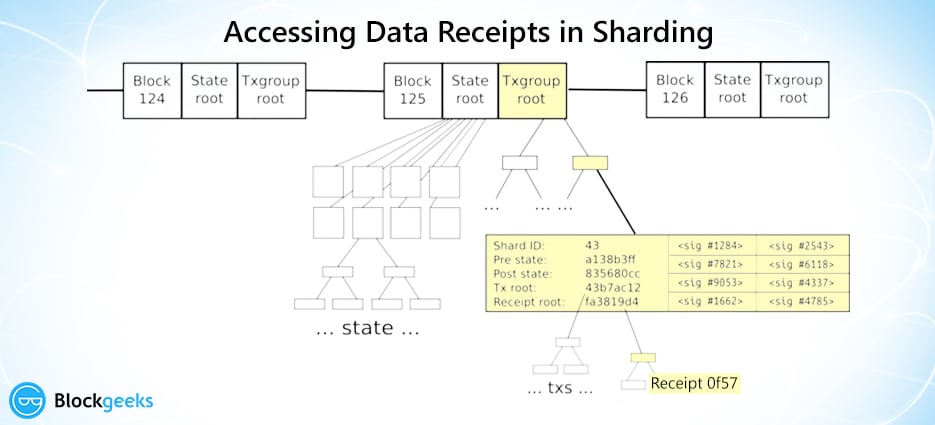
Image courtesy: hackernoon
As you can see here, each individual receipt of any transaction can be easily accessed via multiple Merkle trees from the transaction group Merkle root. Every transaction in a shard will do two things:
- Change the state of the shard it belongs to
- Generate a receipt
Here is another interesting piece of information. The receipts are stored in a distributed shared memory, which can be seen by other shards but not modified. Hence, the cross-shard communication can happen via the receipts like this:
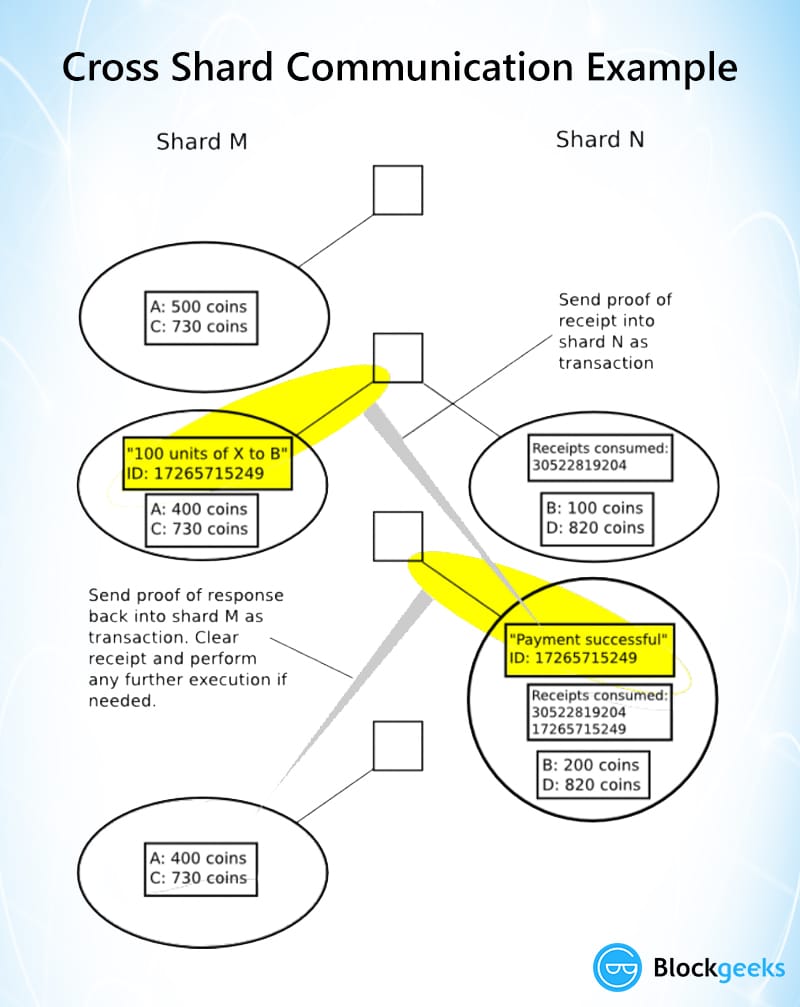
Image courtesy: Hackernoon
What are the challenges of implementing sharding?
- There needs to be a mechanism to know which node implements which shard. This needs to be done in a secure and efficient way to ensure parallelization and security.
- Proof of stake needs to be implemented first to make sharding easier according to Vlad Zamfir.
- The nodes work on a trustless system, meaning node A doesn’t trust node B and they should both come to a consensus regardless of that trust. So, if one particular transaction is broken up into shards and distributed to node A and node B, node A will have to come up with some sort of proof mechanism that they have finished work on their part of the shard.
What are Ethereum Nodes And Sharding: Conclusion
As Ethereum expands and ushers in Metropolis and Serenity, sharding becomes more and more critical to their growth. If ethereum does plan on becoming the new internet, they need to fix their scalability issues. They absolutely need to implement and nail sharding to ensure their growth. Exciting times lie ahead for ethereum!
AMAZONPOLLY-ONLYAUDIO-START-In this guide, you will learn what are ethereum Nodes And Sharding. If you’d like to learn even more, please take a look at our blockchain courses. If you have been active in one form or another in cryptocurrency for the last year then you would know that there has been one issue which has plagued both bitcoin and ethereum: Scalability. Bitcoin has somewhat addressed this issue by activating Segwit and by hard forking into Bitcoin Cash. Ethereum, however, is trying to solve this issue in a different way. One of the many protocols that they are looking to activate, as they go into the next phase of their growth, is “sharding”. Before we understand what that means, we need to have a thorough understanding of networks and nodes.
What are Ethereum Nodes And Sharding? What are nodes, networks, and parameters? Let’s understand what the concept means by using simple day-to-day activities. (Before we begin, credit to 3dBuzz for the wonderful explanation.) Think of a box: This box takes in inputs, performs some sort of operations on them, and then gives an output. This box is a “node”. Keep in mind, nodes are not exactly “boxes”, we are just using a hypothetical case here. A network is a collection of these nodes which are interlinked to one another. Parameters are the rules that the nodes are bound by. That, in essence, is what nodes and networks are. Now let’s check out some simple day-to-day activities explained via nodes and networks. Let’s see how a simple paper shredder works. So, what happened here? You are using three nodes: The paper the shredder and the….well…” shredded stuff”. These three nodes make up the “Shredding network”. Let’s have some more fun with this. Till now, we have assumed that nodes take in only one input. What if they take more than that? Let’s take the example of a toaster. A toaster takes in two inputs: Electricity Bread So this is what it will look like: Remember one thing, a toaster can’t work if even one of its inputs is missing. Now, it’s time to take it up another notch. Let’s think of a complex network, which uses parameters. Think of your television set. Your television set is connected to your service provider. Suppose you own a PS4, and because you suck at making decisions, you own an Xbox as well. So, if we were to map out the whole “TV network”, this is what it would look like: Uh, oh.. we have a problem here. You can only access one of those nodes via your TV. You can’t really watch Game of Thrones and play Uncharted at the same time now, can you? So, how are you going to make sure that your TV can access only one node at a time? This is where you introduce the parameters. The parameters are what make your nodes unique. Suppose, you want to add a parameter to the television called “Channel Switcher”. And this is what the channel switcher works like: If you press “0” then it will show normal TV aka service provider. If you press “1” then you will be able to access PS4. If you press “2” then you will be able to access Xbox. Just by the addition of these parameters you made your node i.e. the television unique. So, let’s explore what other parameters we can give our television to make it more unique: Size: Say, our television is a 55-inch screen. Colour: Our TV is silvery grey in colour. Brand: We have a Sony TV. Type: We have a plasma screen. Ok, so now thanks to our parameters, we have a television which is more well defined. Now we know that we have a 55 inch, silvery grey, plasma screen Sony TV. So, from everything that we have learned so far, let’s try to define what nodes, network and parameters mean. Nodes: Individual components which take in input and performs a function on them and gives out an output. Network: Collection of nodes which are interconnected to one another. Parameters: Rules that define a node and make it more unique Nodes and Network in the context of telecommunications Our entire telecommunications system works on the basis of networks and nodes. Your internet, calls, SMSs, every single one of those work because of carefully laid out networks and nodes. So, how do you define a telecom network? According to Encyclopedia Britannica, “Telecom network is an electronic system of links and switches, and the controls that govern their operation, that allows for data transfer and exchange among multiple users.” Why do we need a telecommunications network? While it is possible to make one-to-one connections between individual people, it will be extremely expensive and cumbersome. Plus, it will be an extremely ineffective process because most of the communication lines will be idle and under/not utilized. To make this process more efficient, we use a telecommunications network. So, what is the definition of a node in this context? In this context, the node is either a redistribution point or a communications end-point. So, let’s see an example of how this works. Consider a simple GSM network. Suppose, Alice wants to send an SMS to Bob, how will the entire system work? (Shoutout to Roviell YouTube channel for the explanation). Step 1: Alice writes the message and presses send. The message goes to the Base Station aka BST. The BST connects you to the network. There are tons of BSTs around. Think of them as waiters in a restaurant. You simply raise your hand (send an SMS) and you get their attention. Step 2: The Base Station Controller aka BSC makes sure that the BSTs are all in order and that everything is in working condition. Using our restaurant analogy, the BSC is the “maître d’hôtel” or the head waiter who makes sure that each table is been attended to by waiters. (Remember Jean Phillippe from Hell’s Kitchen? Yeah, that guy.) Step 3: From the BSC the message now goes to the Mobile Switching Center aka MSC. It makes sure that the data moves seamlessly from the stations to the networks and vice-versa. In our restaurant analogy, the MSC are the head chefs, who take the orders and relay them to the chefs AND also put the finishing touches on the dishes before sending them out. Step 4: Now the message gets sent to the Short Message Service Center aka SMSC. These are the chefs in the analogy. Over here, the message is saved until they get more information about the recipient. The SMSC gets help from sources like the Home Location Register (HLR) and the Visitor Location Register (VLR), these 2 are databases which contain all the information about the network. They basically help track down the sender AND the recipient to see if the message can be sent. They check whether the recipient’s phone is switched off, or if it is out of coverage area etc. If for some reason the message can’t be sent, then it gets stored in the SMSC for a maximum of 6 hours before it gets deleted. Step 5: Now, if the SMS is good to go, the SMSC hands the message over to the recipient’s MSC. Step 6: The SMS goes to the BSC. Step 7: The BSC forwards the message to the BST. Step 8: The BST then finally sends the message to the recipient. So, this is an overview of how the entire SMS system works. The BSC, BST, MSC, SMSC, HLR and VLR are all nodes in the GSM network. This is what the whole thing looks like: What is a Peer-to-Peer Network? A normal network structure is the “client-server” structure. How does that work? There is a centralized server. And everyone who wants to connect with the server can send a query to get the required information. This is pretty much how the internet works. When you want to Google something, you send a query to the Google server, which comes back with the required results. So, this is a client-server system. Now, what is the problem with this model? Since everything is dependent on the server, it is critical for the server to be functioning at all times for the system to work. It is a bottleneck. Now suppose, for whatever reason the main server stops working, everyone in the network will be affected. Plus, there are also security concerns. Since the network is centralized, the server itself handles a lot of sensitive information regarding the clients. This means that anyone can hack the server and get those pieces of information. Plus, there is also the issue of censorship. What if the server decides that a particular item (movie, song, book etc.) is not agreeable and decides not to propagate it in their network? So, to counter all these issues, a different kind of network architecture came about. It is a network which partitions its entire workload between participants, who are all equally privileged, called “peers”. There is no longer one central server, now there are several distributed and decentralized peers. This is a peer-to-peer network. Image Courtesy: InfoZones Why do people use the peer-to-peer network? One of the main uses of the peer-to-peer network is file sharing, also called torrenting. If you are to use a client-server model for downloading, then it is usually extremely slow and entirely dependent on the health of the server. Plus, like we said, it is prone to censorship. However, in a peer-to-peer system, there is no central authority, and hence if even one of the peers in the network goes out of the race, you still have more peers to download from. Plus, it is not subject to the idealistic standards of a central system, hence it is not prone to censorship. If we were to compare the two: Image courtesy: Quora The decentralized nature of a peer-to-peer system becomes critical as we move on to the next section. How critical? Well, the simple (at least on paper) idea of combining this peer-to-peer network with a payment system has completely revolutionized the finance industry by giving birth to cryptocurrency. The use of networks and nodes in cryptocurrencies. Let’s take a look at Ethereum’s network structure. ethereum is structured as a peer-to-peer network, such that the participants aka the peers aka the nodes are not given any extra special privileges. The idea is to create an egalitarian network. The nodes are not given any special privileges, however, their functions and degree of participation may differ. There is no centralized server/entity, nor is there any hierarchy. It is a flat topology. All decentralized cryptocurrencies are structured like that is because of a simple reason, to stay true to their philosophy. The idea is to have a currency system, where everyone is treated as an equal and there is no governing body, which can determine the value of the currency based on a whim. This is true for both bitcoin and ethereum. Now, if there is no central system, how would everyone in the system get to know that a certain transaction has happened? The network follows the gossip protocol. Think of how gossip spreads. Suppose Alice sent 3 ETH to Bob. The nodes nearest to her will get to know of this, and then they will tell the nodes closest to them, and then they will tell their neighbors, and this will keep on spreading out until everyone knows. Nodes are basically your nosy, annoying relatives. So, what is a node in the context of ethereum? A node is simply a computer that participates in the ethereum network. This participation can be in three ways By keeping a shallow-copy of the blockchain aka a Light Client By keeping a full-copy of the blockchain aka a Full Node By verifying the transactions aka Mining What is a Light Client? As we have mentioned before, the idea of a peer-to-peer system is to distribute network responsibilities among nodes called “peers”. No preference is given to any one of them. However, what about people who want to take part in the network but don’t have the system resources to download and maintain the full blockchain in their system? They can choose to become “Light clients”. By being a Light Client, they get high-security assurances about certain states of ethereum and also the power to verify the execution of a transaction. What is a Full Node? Any computer, connected to the ethereum network, which fully enforces all the consensus rules of ethereum is called a Full Node. A full node downloads the entire blockchain in the user’s desktop. Full nodes form the backbone of the ethereum system and keep the entire network honest. Some of the consensus rules that full nodes enforce are: Making sure that the correct block reward is given out for each block mined (5 ETH) Transactions have the correct signatures Transactions and blocks are in the correct data format No double spending is occurring in any of the blocks The full nodes basically validate the nodes and transactions and relay the information to the other nodes (using the gossip protocol). Miners vs Nodes To keep it simple, all miners are full nodes, but not all full nodes are miners. Miners need to be running full nodes to access the blockchain. Anyone who runs a full node need not mine for blocks. What is the scalability problem that Ethereum is facing? How does consensus happen in the ethereum network? Each and every node in the network does every calculation, and when they all come to a consensus, the transaction is deemed good. Now, this might have worked properly, in the beginning, however, ethereum has grown very popular and the number of transactions has been steadily increasing. Check out this graph by Etherscan: Image Courtesy: Etherscan Now, even though this is a good thing, the number of calculations that the networks have to go through before they can come to a consensus has increased exponentially as a result. Along with that, there is another problem that has come up. ethereum has seen widespread adoption because of the backing by certain corporate heavyweights and the popularity of its ICOs. As a result of this, the number of nodes on the ethereum network has increased exponentially. In fact, it is the cryptocurrency with the most nodes and hence most decentralized. In fact, as of May 2017, ethereum had 25,000 nodes as compared to Bitcoin’s 7000!! That’s more than 3 times. In fact, the number of nodes from April to May increase by 81%…that’s nearly double! Image Courtesy: Trust Nodes. Now, you may be thinking that having more nodes in the network will help speed up the transaction time. Well… think again. Consensus happens in a linear manner. Meaning, suppose there are 3 nodes A, B and C. For consensus to occur, first A would do the calculations and verify and then B will do the same and then C. However, if there is a new node in the system called “D”, that would add one more node to the consensus system, which will increase the overall time period. As ethereum has become more popular, the transaction times have gotten slower. In fact, in a speed test, it was seen that ethereum managed a paltry 20 transactions per second as compared to PayPal’s 193 and Visa’s 1667!! Now remember one thing, ethereum doesn’t envision themselves to be just mere currency, their ultimate vision is to be something like the new internet. They want people to create DApps on the scale of Facebook and Youtube to run on top of their blockchain. In order for something like this to happen, they will need to do something about their scalability issues. In order to address that, three proposals were raised: Increase the block size Make users use different alt coins Sharding Increase the block size So, one solution is to increase the block size. While this would definitely improve the performance by increasing the number of transactions going into one block, there are several problems that can happen as a result: Firstly, this will still not solve the problem of nodes coming to a consensus at a slower pace. In fact, as the number of transactions per block increases, the number of calculations and verifications per node will increase as well. In order to accommodate for more and more transactions, the block sizes need to be increased periodically. This will centralize the system more because normal computers and users won’t be able to download and preserve such bulky blockchains. This goes against the egalitarian spirit of a blockchain. Finally, block size increase will happen only via hardfork, which can split the community. The last time a major hardfork happened in ethereum the entire community was divided and two separate currencies came about. People don’t really want this to happen again. Make users use different altcoins. Another proposal was to run parallel blockchains instead of one main blockchain. Basically, instead of making 50 DApps run on one main blockchain, have 2 blockchains and run 25 DApps each. There were two problems with this proposal: It is not wise to split up the hashrate of a chain. The hashrate of the chain after all determines how secure it is from external hackers and fast the system is. It will be easier for malicious miners to get 51% majority on the smaller chains. Sharding Finally, sharding was decided as the way to go for ethereum. Before we do a deep dive into sharding let’s gain a simple understanding as to what it means. Suppose there are three nodes A, B and C and they have to verify data T. Instead of A, B and C verifying the entire data T individually, the data will be broken into 3 shards: T1, T2 and T3. After that A, B and C will verify one shard each side-by-side. As you can see the amount of time you are saving is exponential. Anyway, let’s do a deep dive! What is sharding? Sharding is a term that has been taken from database systems. Let’s see what sharding means with respect to the database. Suppose you have a huge bulky database for your website. Having a bulky database not only makes searching for data slower, but it also hinders your scalability. So, what do you do in this case? What if you do a horizontal partition on your data and turn them into smaller tables and store them on different database servers? Image courtesy: Dzone Like so? Now, you might be asking, why a horizontal partition and not a vertical partition? That is because of the way tables are designed: You see? It is the same table/database but with lesser data. These smaller databases are known as shards of the larger database. Each shard should be identical with the same table structure. Sharding in the context of blockchain Now, as we have seen, the problem with ethereum consensus is that all the nodes need to do all the calculations and verifications for each and every transaction. This makes the whole process very slow and cumbersome. So, how is sharding going to help this? Consider the state of the ethereum blockchain which we shall call “Global State”, which is visible to everyone. Let’s consider the Merkle Root of this global state. (For Merkle trees and roots read our article on HASHING). This state root is going to be broken up into shard roots and each of these shared roots is going to have their own state. These states are going to be represented in the form of a Merkle tree. This is a very simple structure of what that is supposed to look like. Now, let’s get into the internal mechanics. So what happens what after sharding is activated? The state is split into shards Each unique account is in one shard Accounts can only transact with other accounts in the same shard In Devcon, Vitalik Buterin explained shards like this: Imagine that ethereum has been split into thousands of islands. Each island can do its own thing. Each of the island has its own unique features and everyone belonging on that island i.e. the accounts, can interact with each other AND they can freely indulge in all its features. If they want to contact with other islands, they will have to use some sort of protocol. So, the question is, how is that going to change the blockchain? What does a normal block in bitcoin or ethereum (pre-sharding) look like? So, there is a block header and the body which contains all the transactions in the block. The Merkle root of all the transactions will be in the block header. Now, think about this. Did bitcoin really need blocks? Did it really need a blockchain? Satoshi could have simply made a chain of transactions by including the hash of the previous transaction in the newer transaction, making a “transaction chain” so to speak. The reason why they arrange these transactions in a block is to create one level of interaction and make the whole process more scalable. What ethereum suggests is that they change this into two levels of interaction. The First Level The first level is the transaction group. Each shard has its own group of a transaction. Image courtesy: Hackernoon The transaction group is divided into the transaction group header and the transaction group body. Transaction Group Header The header is divided into distinct left and right parts. The Left Part: Shard ID: The ID of the shard that the transaction group belongs to. Pre-state root: This the state of the root of shard 43 before the transactions were applied. Post state root: This is the state of the root of shard 43 after the transactions are applied. Receipt root: The receipt root after all the transactions in shard 43 are applied. The Right Part: The right part is full of random validators who need to verify the transactions in the shard itself. They are all randomly chosen. Transaction Group Body It has all the transaction IDs in the shard itself. Properties of Level One Every transaction specifies the ID of the shard it belongs to. A transaction belonging to a particular shard shows that it has occurred between two accounts which are native to that particular shard. Transaction group has transactions which belong to only that shard ID and are unique to it. Specifies the pre and post state root. Now, let’s look at the top level aka the second level. The Second Level Image courtesy: Hackernoon. Don’t be scared! It is easier to understand than it looks. There is the normal blockchain, but now it contains two primary roots: The state root The transaction group root The state root represents the entire state, and as we have seen before, the state is broken down into shards, which contain their own substates. The transaction group root contains all the transaction groups inside that particular block. Properties Of Level Two Level two is like a simple blockchain, which accepts transaction groups rather than transactions. Transaction group is valid only if:a) Pre-state root matches the shard root in the global state. b) The signatures in the transaction group are all validated. If the transaction group gets in, then the global state root becomes the post-state root of that particular shard ID. So how does cross-shard communication happen? Now, remember our island analogy? The shards are basically like islands. So how do these islands communicate with each other? Remember, the purpose of shards is to make lots of parallel transactions happen at the same time to increase performance. If ethereum allows random cross-shard communication, then that defeats the entire purpose of sharding. So what protocol needs to be followed for cross-shard communication? ethereum chose to follow the receipt paradigm for cross-shard communications. Check this out: Image courtesy: hackernoon As you can see here, each individual receipt of any transaction can be easily accessed via multiple Merkle trees from the transaction group Merkle root. Every transaction in a shard will do two things: Change the state of the shard it belongs to Generate a receipt Here is another interesting piece of information. The receipts are stored in a distributed shared memory, which can be seen by other shards but not modified. Hence, the cross-shard communication can happen via the receipts like this: Image courtesy: Hackernoon What are the challenges of implementing sharding? There needs to be a mechanism to know which node implements which shard. This needs to be done in a secure and efficient way to ensure parallelization and security. Proof of stake needs to be implemented first to make sharding easier according to Vlad Zamfir. The nodes work on a trustless system, meaning node A doesn’t trust node B and they should both come to a consensus regardless of that trust. So, if one particular transaction is broken up into shards and distributed to node A and node B, node A will have to come up with some sort of proof mechanism that they have finished work on their part of the shard. What are Ethereum Nodes And Sharding: Conclusion As ethereum expands and ushers in Metropolis and Serenity, sharding becomes more and more critical to their growth. If ethereum does plan on becoming the new internet, they need to fix their scalability issues. They absolutely need to implement and nail sharding to ensure their growth. Exciting times lie ahead for ethereum!-AMAZONPOLLY-ONLYAUDIO-END-






Distill the entire Ethereum ecosystem down to the least amount of code without hindering the coin/token?
Very thorough article, many thanks.